Software
Speech Recognizers
Microsoft SAPI (http://msdn.microsoft.com/library/en-us/SAPI51sr/html/SAPI5_Overview.asp)
The SAPI application programming interface (API) dramatically reduces the code overhead required for an application to use speech recognition and text-to-speech, making speech technology more accessible and robust for a wide range of applications. The SAPI API provides a high-level interface between an application and speech engines. SAPI implements all the low-level details needed to control and manage the real-time operations of various speech engines.
The two basic types of SAPI engines are text-to-speech (TTS) systems and speech recognizers. TTS systems synthesize text strings and files into spoken audio using synthetic voices. Speech recognizers convert human spoken audio into readable text strings and files.
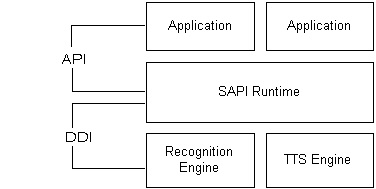
Events
SAPI communicates with applications by sending events using standard callback mechanisms (Window Message, callback proc or Win32 Event). For TTS, events are mostly used for synchronizing to the output speech. Applications can sync to real-time actions as they occur such as word boundaries, phoneme or viseme (mouth animation) boundaries or application custom bookmarks.
Lexicons
Applications can provide custom word pronunciations for speech synthesis engines using methods.
LumenVox's Speech Recognition Engine (http://www.lumenvox.com/htm/products/speech_engine/main.asp)
The Speech Engine provides speech application developers with an efficient development and runtime platform, allowing for dynamic language, grammar, audio format, and logging capabilities to customize every step of their application. Grammars are entered as a simple list of words or pronunciations, or in the industry standard Speech Recognition Grammar Specification (SRGS), as defined by the W3C.
Components of a Speech Recognition Engine
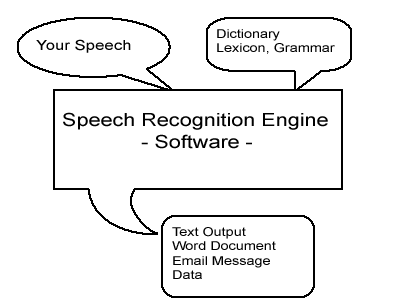
SpeechStudio (http://www.speechstudio.com/suite.htm)
An Integrated Speech Development Environment for rapidly constructing, integrating, or prototyping speech and telephony applications. Developers can quickly voice-enable desktop and Tablet PC applications with speech-recognition, dictation, text-to-speech, audio prompts, audio recording, and telephony.
DynaSpeak (http://www.speechatsri.com/products/dynaspeak.shtml)
DynaSpeak is a small footprint, high accuracy speaker independent speech recognition engine that scales from embedded to large scale system use in industrial, consumer, and military products and systems. The DynaSpeak engine can be ported to a variety of processor/operating system configurations, giving flexibility in product design. DynaSpeak supports both finite state grammars - used in more traditional command and control style applications - and statistical language models - used in more advanced natural language style dialog applications. Because DynaSpeak has been developed for field-oriented embedded applications, it incorporates SRI-developed patented techniques that increase recognition performance using speaker adaptation, microphone adaptation, end of speech detection, distributed speech recognition, and noise robustness.
for Command and Control and for Dictation
Voice Command Recognition Technology SDK (http://www.speechpro.com/production/?id=640&fid=44#p2)
Original speaker dependent or speaker independent voice recogniton algorithm.
SALT (Speech Application Language Tags)
A new software standard developed (for multiple system platforms) by a group of companies (Microsoft, Intel, Cisco, Comverse, Philips, and Spechworks). SALT extends existing Web document formats, such as HTML and XML to enable non-computing devices to access content from the web. SALT also allows computer users to interact with websites using speech text and speech recognition.
SALTforum (http://www.saltforum.org/)
FAQ's, white papers, and newsletter about Speech Application Language Tags
VoiceXML
Envox 6 (http://www.envox.com/software/voicexml.asp)
VoiceXML based communications development platform, adheres to the VoiceXML 2.0 specification and enables rapid development of VoiceXML based voice solutions.
VoiceXML (http://www.w3.org/Voice/)
VoiceXML 2.0 is based upon extensive industry experience. It is designed for creating audio dialogs that feature synthesized speech, digitized audio, recognition of spoken and DTMF key input, recording of spoken input, telephony, and mixed initiative conversations.
VoiceXML Resource Center (http://www.palowireless.com/voicexml/)
From Palo Wireless
Goals of VoiceXML
VoiceXML's main goal is to bring the full power of Web development and content delivery to voice response applications, and to free the authors of such applications from low-level programming and resource management. It enables integration of voice services with data services using the familiar client-server paradigm.
VoiceXML is a markup language that (source: W3C Recommendations)
- Minimizes client/server interactions by specifying multiple interactions per document.
- Shields application authors from low-level, and platform-specific details.
- Separates user interaction code (in VoiceXML) from service logic (e.g. CGI scripts).
- Promotes service portability across implementation platforms. VoiceXML is a common language for content providers, tool providers, and platform providers.
- Is easy to use for simple interactions, and yet provides language features to support complex dialogs.
Speech Software Development Kits
Chant® SpeechKit® (http://www.chant.net/speechkit/default.asp)
Develop software that speaks and listens with Chant® SpeechKit® components. Interface between your software and SAPI 4/SAPI 5. Whether you develop desktop, server, mobile, telephony, Internet software, or web pages, SpeechKit® components can transform text to speech for audio playback and speech to text for your software to process. This liberates your software from keypads, keyboards, and mice as primary input devices by letting end users talk with it
Hidden Markov Model Toolkit (HTK) (http://htk.eng.cam.ac.uk/)
A portable toolkit for building and manipulating hidden Markov models. HTK is primarily used for speech recognition research although it has been used for numerous other applications including research into speech synthesis, character recognition and DNA sequencing. HTK is in use at hundreds of sites worldwide.
Statistical Speech Recognition
description****** (http://www.neuvoice.com/support/index.php#04)
Statistical speech recognition allows the use of context to improve recognition accuracy. For example take the sentence “my name is Alexis Kirke and my address is X, and my telephone number is Y”. Suppose that the speech recognition system thinks it heard the word “plumber” rather than “number”. A good statistical speech recognition system would know that there is a much higher probability of the word “number” appearing at that point in the sentence, than of the word “plumber” appearing there.
Copyright © 2007
voice-commands.com All Rights
Reserved.
Send questions or comments to
webmaster
-commands.com
Or use the feedback form:
here
Thank you.
Related websites:
e-Speaking
Say-Now